GoogLeNet
A Deep Dive into Google’s Neural Network Technology

Master's student @Trinity College Dublin | Loves solving complex problems through intelligent systems | Exploring jobs in tech
GoogLeNet, also known as Inception-v1, stands as a landmark achievement in the realm of convolutional neural networks (CNNs). Unveiled by researchers at Google in 2014, It introduced a novel approach to designing deep networks that not only achieved exceptional accuracy but also demonstrated remarkable computational efficiency. This article delves into the architectural intricacies, design principles, and profound impact of GoogLeNet on the landscape of deep learning.
Previous CNN architectures, such as LeNet-5 and AlexNet, were typically shallow, meaning they had a limited number of layers. This limited their ability to learn complex patterns in data. Additionally, these architectures were not very computationally efficient, meaning they required a large amount of processing power to train and run.
If you want to learn more about other CNN Architectures, check out my previous explained blogs on LeNet-5, AlexNet, and Resnet
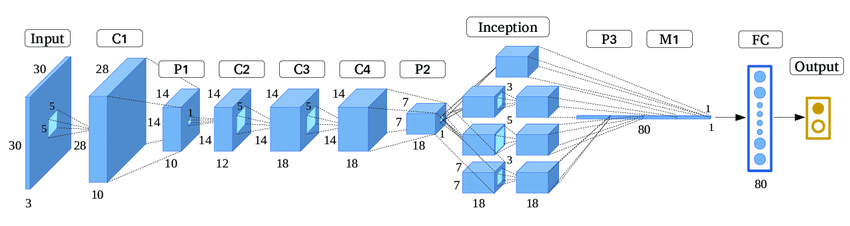
🏞️ GoogLeNet (Inception v1) architecture
One of the main challenges with increasing the depth of CNNs is that it can lead to the problem of vanishing gradients. This is because as the network becomes deeper, the gradients of the loss function with respect to the weights of the network become smaller and smaller. This makes it difficult for the network to learn effectively.
Another challenge with increasing the depth of CNNs is that it can lead to an explosion in computational requirements. This is because the number of computations required to propagate an input through a deep network grows exponentially with the depth of the network.
🔫 Bringing Inception Modules into the picture
GoogLeNet addressed the challenges of previous CNN architectures by introducing the concept of inception modules. Inception modules are a type of building block that allows for the parallel processing of data at multiple scales. This allows the network to capture features at different scales more efficiently than previous architectures.
An inception module typically consists of several convolutional layers with different filter sizes. These layers are arranged in parallel, so that the network can process the input data at multiple resolutions simultaneously. The output of the convolutional layers is then concatenated and passed through a pooling layer. However, later there were various versions of the inception module which was integrated accordingly in the architecture which consisted of different layers and filter size patterns.
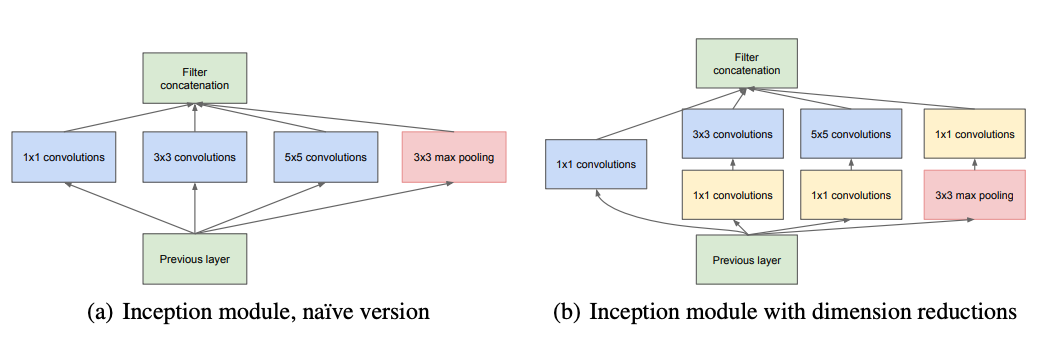
This parallel processing approach has several advantages. First, it allows the network to capture features at different scales more efficiently. This is because the network can process the input data at multiple resolutions simultaneously, which allows it to capture both large-scale and small-scale features. Second, it helps to alleviate the problem of vanishing gradients. This is because the parallel processing approach allows the network to learn features at multiple scales, which can help to stabilise the training process.
The inception module allows the network to capture information at different scales. The inception module is made up of four paths:
1x1 convolution: This path applies a 1x1 convolution to the input. This reduces the number of channels in the input, which helps to reduce the computational complexity of the network.
3x3 convolution: This path applies a 3x3 convolution to the input. This is a standard convolutional operation that is used to extract features from the input image.
5x5 convolution: This path applies a 5x5 convolution to the input. This path is used to capture larger-scale features from the input image.
Max pooling: This path applies a max pooling operation to the input. This operation reduces the size of the input by keeping the maximum value in each 2x2 window.
The outputs of the four paths are then concatenated together, and a 1x1 convolution is applied to the result. This final 1x1 convolution helps to reduce the number of channels in the output, and also helps to improve the accuracy of the network.
⚡️ Global Average Pooling
This technique is commonly used in most of the Convolutional Neural Networks to reduce the total number of parameters and to minimise overfitting. Generally it is placed at the end of the CNN architecture.
Global Average Pooling performs an average operation across the Width and Height for each filter channel separately. This reduces the feature map to a vector that is equal to the size of the number of channels. The output vector captures the most prominent features by summarizing the activation of each channel across the entire feature map.
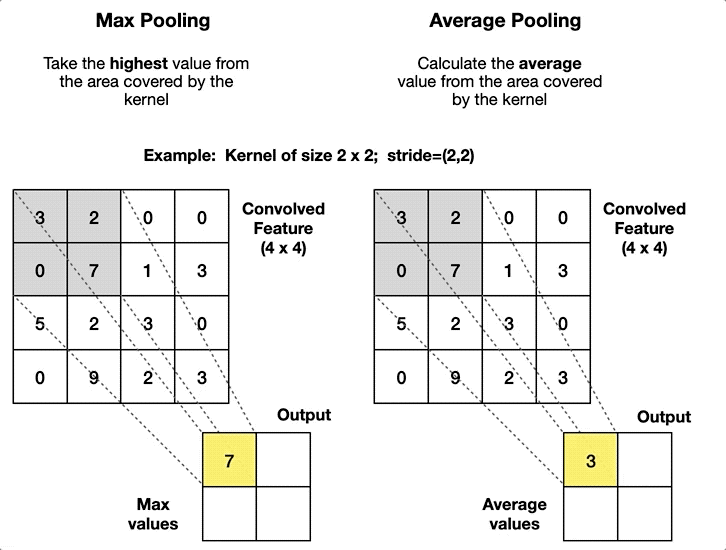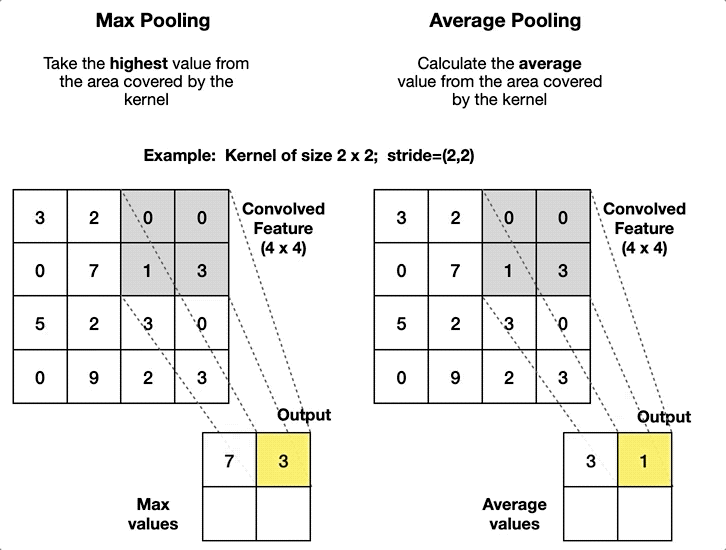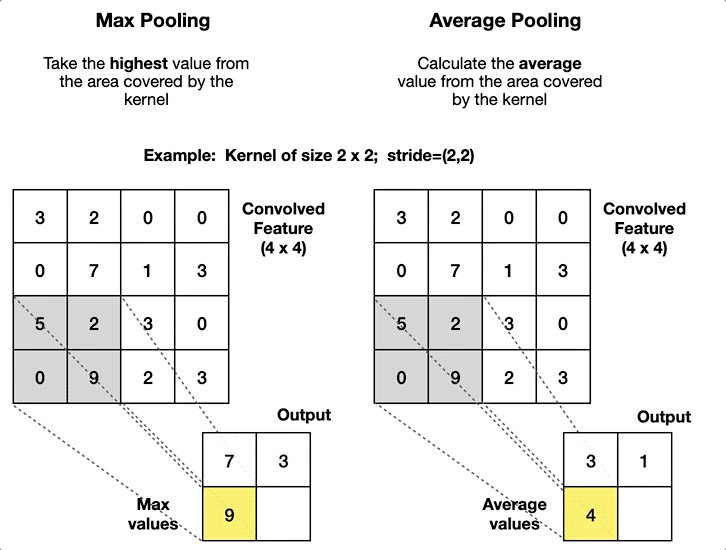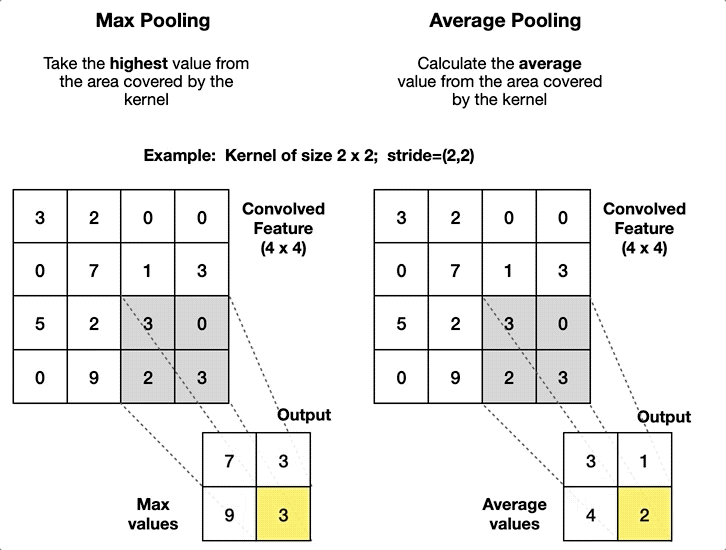
Average Pooling is opposite that the technique that is used in the max pooling, to know more about max pooling you can head to this article which will give you more proper understanding of the method: Understanding Convolutional Neural Networks: Part 1
In GoogLeNet architecture, replacing fully connected layers with global average pooling improved the top-1 accuracy by about 0.6%. In GoogLeNet, global average pooling can be found at the end of the network, where it summarises the features learned by the CNN and then feeds it directly into the SoftMax classifier.
🧮 Auxillary Classifiers
These classifiers helps to overcome the issues that are faced commonly by neural networks known as vanishing gradient problem. These classifiers are placed on the side of the network and are only included in training and not during inferences or testing.
In the GoogLeNet architecture, there are two auxiliary classifiers in the network. They are placed strategically, where the depth of the feature extracted is sufficient to make a meaningful impact, but before the final prediction from the output classifier. The structure of each auxiliary classifier is mentioned below:
An average pooling layer with a 5×5 window and stride 3.
A 1×1 convolution for dimension reduction with 128 filters.
Two fully connected layers, the first layer with 1024 units, followed by a dropout layer and the final layer corresponding to the number of classes in the task.
A SoftMax layer to output the prediction probabilities.
These auxiliary classifiers help the gradient to flow and not diminish too quickly, as it propagates back through the deeper layers. Moreover, the auxiliary classifiers also help with model regularisation. Since each classifier contributes to the final output, as a result, the network is encouraged to distribute its learning across different parts of the network. This distribution prevents the network from relying too heavily on specific features or layers, which reduces the chances of overfitting. This is what makes training possible.
📌 GoogLeNet Versions
GoogLeNet (Inception v1) became a lot successful during the initial introduction to the computer vision community. Therefore, due to this several variants were developed to improve the efficiency of the architecture. Versions like Inception-v2, v3, v4 and ResNet hybrids were introduced. Each of these models introduced key improvements and optimizations, addressing various challenges, and pushing the boundaries of what was possible with the CNN architectures.
Inception v2 (2015): The second version of Inception was modified with improvements such as batch normalisation and shortcut connections. It also refined the inception modules by replacing larger convolutions with smaller, more efficient ones. These changes improved accuracy and reduced training time.
Inception v3 (2015): The v3 model further refined Inception v2 by using atrous convolution (dilated convolutions that expand the network’s receptive field without sacrificing resolution and significantly increasing network parameters).
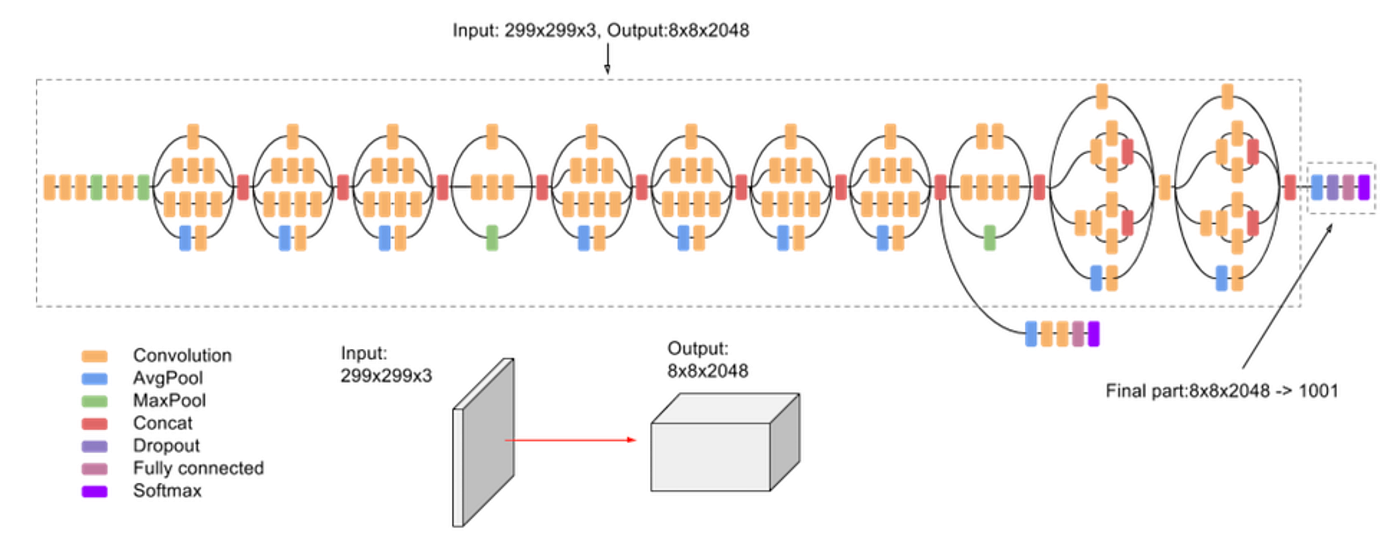
🏞️ Inception v3
Inception v4, Inception-ResNet v2 (2016): This version of Inception introduced residual connections (inspired by ResNet) into the Inception lineage, which led to further performance improvements.
📌 Key Points
GoogLeNet introduced inception modules, revolutionising CNN design by enabling parallel processing at multiple scales.
Its architecture addressed challenges like vanishing gradients and computational efficiency, boosting both accuracy and speed.
Global average pooling replaced fully connected layers, enhancing accuracy and reducing overfitting.
Auxiliary classifiers aided gradient flow and regularisation, making training more efficient and preventing over-reliance on specific features.
GoogLeNet’s inception modules have indeed led to significant improvements in performance and efficiency. As well as added advantages compared to that of previous architectures like feature extraction at multiple scales and alleviating the problem of vanishing gradients
In addition to these advantages, GoogLeNet has also been shown to be more versatile than previous CNN architectures. It has been successfully applied to a variety of tasks, including image classification, object detection, and image segmentation.



