Why Convolutions?

Master's student @Trinity College Dublin | Loves solving complex problems through intelligent systems | Exploring jobs in tech
✨ Good day, readers! ✨
This blog is the first in a series about computer vision. I’ve started learning computer vision and will use this medium to keep up with what I’ve learned and researched on the subject.
💭 This blog was inspired by another Jovian blog created by Paul Bindass. I’d like to give him credit for his blog, and if anyone is interested in learning more about this topic, I recommend checking out his blog — Till now in MLP
Since the day they were invented, neural networks have progressed. It’s been utilised for a variety of purposes, mostly in Deep Learning and Artificial Intelligence. Computer Vision, also known as Machine Vision, is a popular field that has experienced a lot of changes in recent years. And we’ll speak about why Computer Vision was created in the first place. Why were Convolutions required, and how did they alter the way artificial neural networks operate?
MLP, or Multi-Layer Perceptron, has greatly improved, and tools such as TensorFlow and PyTorch have made it easier for developers with some additional programming experience to create such systems.
Detecting and Extracting Information from Image Datasets Using MLP was a very straightforward process as shown below, however, it had significant downsides.
Here a normal sequential model has been used, for forward and backward propagation. Flatten and Dense function for creating input layers for our neural network, where one flatten layer is used and three dense layers with two activation functions as ‘Relu’ and one activation function as ‘SoftMax’.
Flatten function is used to convert the 2D object (i.e. Image) into a 1D array. The Input shape is (28, 28) which means, that the image used has dimensions of 28, 28 (Images from MNIST dataset)
Params after the flattened layer = 0 because this layer only flattens the image to a vector for feeding into the input layer. The weights haven’t been added yet.
Params after layer 1 = (784 nodes in input layer) × (512 in hidden layer 1) + (512 connections to biases) = 401,920.
Params after layer 2 = (512 nodes in hidden layer 1) × (512 in hidden layer 2) + (512 connections to biases) = 262,656.
Params after layer 3= (512 nodes in hidden layer 2) × (10 in output layer) + (10 connections to biases) = 5,130.
Total params in the network = 401,920 + 262,656 + 5,130 = 669,706.
💡 Why Convolutions?
📌 SPATIAL INVARIANCE or LOSS IN FEATURES
The spatial features of a 2D image are lost when it is flattened to a 1D vector input. Before feeding an image to the hidden layers of an MLP, we must flatten the image matrix to a 1D vector, as we saw in the above code block. This implies that all of the image’s 2D information is discarded.

🖼 Sample Image that has been extracted
After the image has been extracted, it is turned into machine-readable text or numbers. For further image processing, each pixel is transformed into a matrix. This would have been different in the MLP, the pixels would have merged into one single matrix making it difficult to extract patterns and edges as well as relevant information from the image.
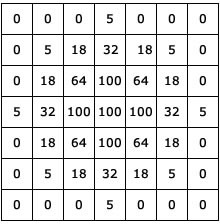
🖼 Sample Matrix that has been extracted
📌 Increase in Parameter Issue
While an increase in Parameter Issue is not a big problem for the MNIST dataset because the images are really small in size (28 × 28), what happens when we try to process larger images?
For example, if we have an image with dimensions 1,000 × 1,000, it will yield 1 million parameters for each node in the first hidden layer.
- So if the first hidden layer has 1,000 neurons, this will yield 1 billion parameters even in such a small network. You can imagine the computational complexity of optimizing 1 billion parameters after only the first layer.
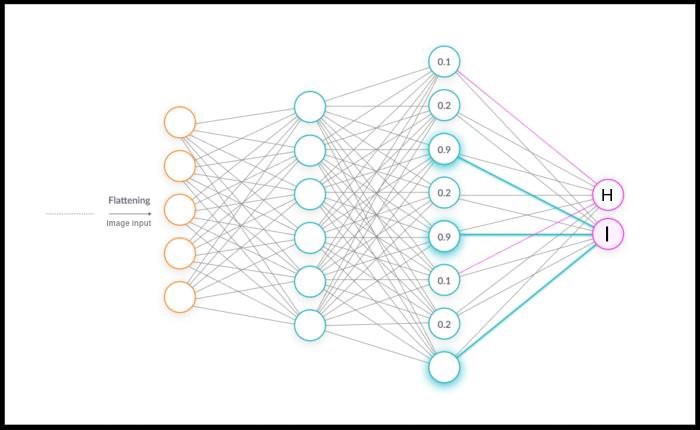
🖼 Fully Connected Network
Dense layers are the hidden layers in a neural network that are used to train the inputs. However, having more dense layers has the disadvantage of slowing down the training process. As a result, as model developers, we must select how many dense layers to include in the design.
People later realised that dense layers were causing a problem because, while training dense layers on images, all of the features of the images were jumbled after each round of training, making the training process more complex. The developers used locally connected neural networks to solve this problem.
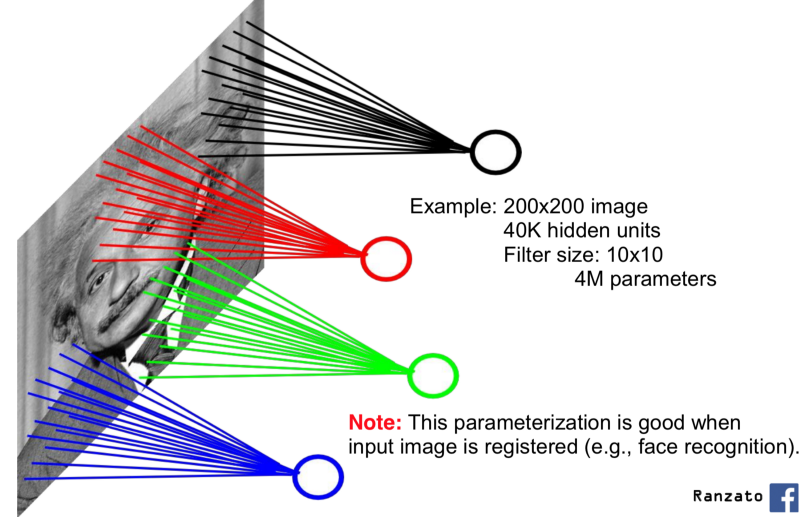
🖼 Local Connected Neural Net
📌 Guide for design of a neural network architecture suitable for computer vision
In the earliest layers, our network should respond similarly to the same patch, regardless of where it appears in the image. This principle is called translation invariance.
The earliest layers of the network should focus on local regions, without regard for the contents of the image in distant regions. This is the locality principle. Eventually, these local representations can be aggregated to make predictions at the whole image level.
Edges -> Patterns -> Parts of Objects -> Objects -> Image, is the general intuition of the output generated by the early layers to the last layers of CNN.
🧠 Human Brain Visual Cortex processing
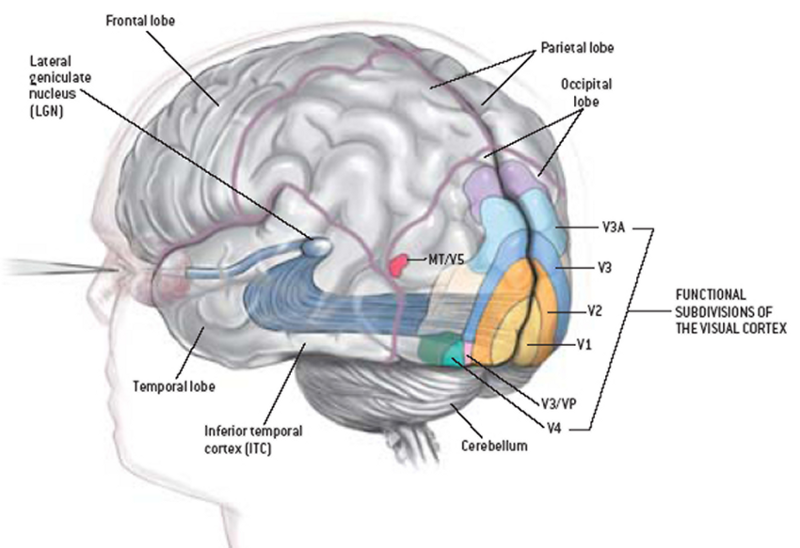
While capturing an image from the eyes, the human brain processes the visuals in the same way as that of the locally connected neural network. However human brain uses more layers (functional subdivisions of the visual cortex) to get the patterns and objects in the real world.
👁 Human eye colour sensitivity
The human eye can mostly extract information in an RGB format (Red, Green, Blue) also called BGR. In the same way, neural networks too can extract information from the image using the colour channels. There are many colour channels in a neural network that can help to collect image information although the most widely used colour channels are. RGB and CYMK (Basically for printing purposes, and also good for transparency reading)
Hypothetically if in RGB, there are 3 channels red, green and blue. The features are extracted from each channel and stored in a container or a bucket that process is called a Feature Map. Channels can vary from 3 to 512.
💡 Key points
Multi-layer perceptron is not accurate for Image processing or computer vision problem statements.
Convolutions helped to fix the drawback created by MLP, by creating various matrices of the pixels that were generated by the layers.
A Fully Connected Neural Network can create high computation problems so to avoid that, Locally Connected neural networks are used that divide images into patches and extract features from the patches.
Edges -> Patterns -> Parts of Objects -> Objects -> Image, is the general intuition of the output generated by the early layers to the last layers of CNN.
With help of Colour Channels, the features of an image are extracted. Wide colour channels used for feature extraction are RGB and CYMK.
A feature map is a container or a bucket which stores the information or the features that are collected from each of the colour channels.
We’ll talk more about Convolutions and Convolution Neural Networks in the next section, as well as try to learn more about Convolution Kernels, Channels, and Operations.
Next Blog — Understanding Convolution Neural Networks (Part 1)




