Introduction to ML Ops

Master's student @Trinity College Dublin | Loves solving complex problems through intelligent systems | Exploring jobs in tech
“MLOps is an approach to managing machine learning projects. It can be thought of as a discipline that encompasses all the tasks related to creating and maintaining production-ready machine learning models. MLOps bridges the gap between data scientists and operation teams and helps to ensure that models are reliable and can be easily deployed.” — Pratik Sharma
A set of procedures called MLOps or ML Ops attempts to effectively and reliably deploy machine learning models in production. The term is a combination of “machine learning” and DevOps, a continuous development methodology used in the software industry. In solitary experimental systems, machine learning models are constructed and tested. When an algorithm is prepared for release, Data Scientists, DevOps, and Machine Learning engineers practise MLOps to move the algorithm to production systems.
MLOps aims to boost automation and raise the calibre of production models while concentrating on business and regulatory needs, much as DevOps or Data Ops approaches. MLOps began as a set of best practices but is gradually becoming a stand-alone method of managing the ML lifecycle. The complete lifecycle is covered by MLOps, which includes integration with model creation (software development lifecycle, continuous integration/continuous delivery), orchestration, and deployment, as well as health, diagnostics, governance, and business metrics. MLOps is a part of Model Ops, claims Gartner. While Model Ops addresses the operationalization of all AI model types, MLOps is concentrated on the operationalization of ML models.
Why do we need ML Ops?
Why is the MLOps strategy required? Would it not be possible to simply store our models on ever-larger computing platforms that would enable them to manage massive amounts of data and traffic? The truth is somewhat more nuanced.
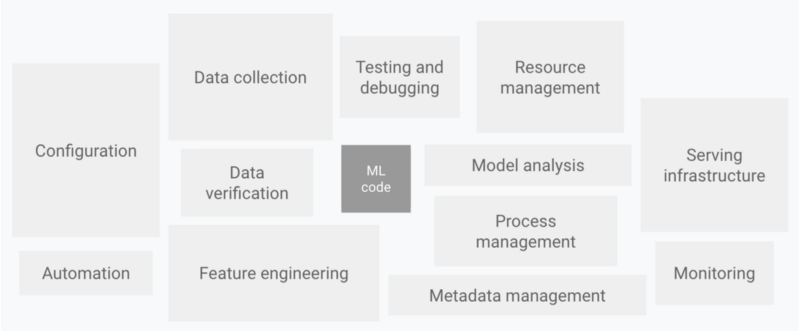
The above figure shows a few of the typical elements present in production-level ML systems. We can see that there is a lot more to the system than the model, or ML, code when it comes to developing useable models that are coupled with other software applications. The ML code is frequently only a minor component of the larger ecosystem. Consider the serving infrastructure. Without an interface to deliver model predictions to client apps or users in an integrated system, our model predictions are effectively meaningless. Many various aspects of this infrastructure must be taken into account, such as the techniques by which predictions are served, how/if common forecasts are stored in a database or cache, and data security issues.
These technologies can easily become cumbersome if the appropriate structures and management procedures are not in place. The issue with large-scale ML systems cannot be solved by merely increasing the available computing power.
The author of the study “Hidden Technical Debt in Machine Learning Systems” has investigated many ML-specific risk factors to take into account in system design and has amply indicated the large ongoing maintenance expenses in real-world ML systems. Boundary erosion, entanglement, covert feedback loops, undeclared consumers, data dependencies, configuration problems, shifts in the outside world, and several system-level anti-patterns are some of these.
Machine Learning Pipelines
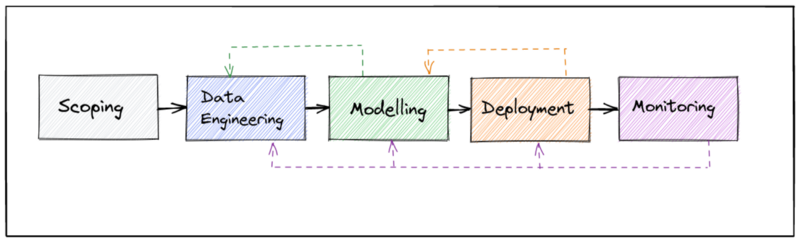
Let’s first take a broad look at what a standard machine learning pipeline entails before exploring how we would organise ML pipelines to achieve MLOps’ objectives. The above figure illustrates how an ML project can be divided into five broad stages.
Scoping: Scoping is the process of creating the design specifications for the system that will use machine learning to tackle the problem at hand.
Data Engineering: Establishing data collection techniques, cleaning data, EDA, and feature engineering/transformation activities required to get the data into the format used as input to the model are all examples of data engineering.
Modelling: Modelling involves training the model(s), analysing errors, and comparing results to benchmarks.
Deployment: The finished model is packaged for use in production during deployment.
Monitoring: Tracking the models and the serving performance, looking for errors or data drift.
These final four steps are crucial in assisting us in creating a machine-learning pipeline that guides us through the whole model lifecycle. If we are just interested in developing one model, performing these steps manually is a fantastic place to start. However, in most circumstances, it is necessary to iterate and create new models. And this is where applying the MLOps concepts will allow us to iterate rapidly and efficiently.
Including MLOps into the Machine Learning Pipeline
1. A templated strategy should be used for the ML pipeline.
First and foremost, there isn’t much we can do in terms of orchestration if our pipeline isn’t constructed in a way that allows one stage to flow into the next. Our pipelines should be designed from the beginning so that each stage can work with the next without much resistance or extra involvement. We can avoid a great deal of unnecessary stress while trying to get our system to function in the first place if we can design a template for the pipeline.

2. Iterable and reproducible machine learning models should be used.
We should be able to quickly identify the datasets and settings utilised to train our models as part of our pipeline. We can retrace the various processes that went into training a particular model by building reproducible pipelines with proper versioning and metadata management (with the understanding that many non-deterministic models have some degree of randomness associated with the training, and may deviate from iteration to iteration). Without this reproducibility, we are unable to understand the process used to build our models, which makes it challenging to prioritise potential problems. Additionally, a repeatable pipeline makes it possible to iterate on earlier models by using the same pipeline stages and only altering the relevant parameters (such as the dataset) to produce new model iterations.
3. The ML pipeline needs to be expandable.
We want our ML pipeline to be able to scale against this increased demand as both the input and output of the models grow (both in terms of dataset and usage). Our pipelines should be able to manage additional traffic and usage from end-users and clients in addition to being able to assign more computing power to train bigger models or models on bigger datasets. Our models might take too long to train or, worse, lose their ability to manage the volume of data without this scalability. Increased traffic could completely crash our application on the service side. Fortunately, many of the widely used frameworks discussed earlier make it simple to explicitly include this dimension as part of their design patterns.
4. The entire ML workflow should be automated.
We now have all we need to automate our pipeline thanks to a pipeline that adheres to a solid foundation and is repeatable, Iterable, and scalable. The core of MLOps is building automated pipelines. We can rapidly, efficiently, and without any manual intervention deliver new versions of models thanks to automated machine learning (ML) pipelines. This can be quite helpful in a world where data is continuously changing and where our ground truth might change drastically.
The MLOps process’ maturity is determined by the extent of automation, which may be divided into three categories:
Level 0: Manual procedure
Level 1: Automation of the ML pipeline
Level 2: Automation of the CI/CD pipeline
Level 0: Manual Process
Although many teams have data scientists and machine learning experts who can create cutting-edge models, their method for creating and deploying ML models is completely manual. Level 0 maturity is regarded as being at this level. The workflow of this technique is depicted in the diagram below.
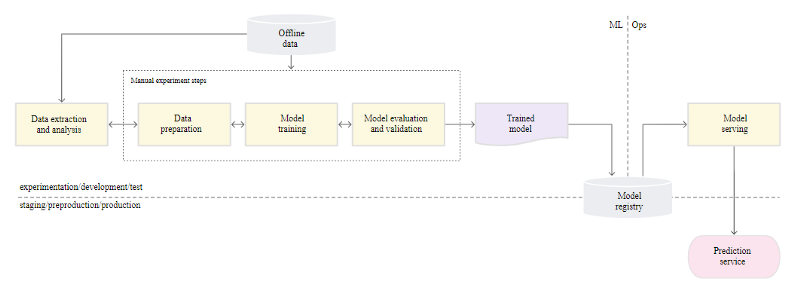
Interactive, script-driven, and manual processes: Data preparation, analysis, model training, and validation are all manual processes. Each step must be completed manually, as well as the transition from one phase to the next. Until a usable model is created, this process is typically driven by experimental code that data scientists write and run interactively in notebooks.
Disconnection between machine learning and operations: In this approach, engineers serve as the model’s prediction service while data scientists are responsible for its creation. The engineering team receives a trained model from the data scientists to deploy on their API infrastructure. The trained model can be transferred by verifying the model object into a code repository, uploading it to a model registry, or placing it in a storage location. The model must then be deployed by engineers who make the necessary features available in the production environment for low-latency serving, which may result in training-serving skew.
It is assumed that your data science team handles a small number of models that don’t change regularly, either in terms of model implementation or model retraining using fresh data. Only a few times a year is a new model version deployed.
No Continuous Integration: CI is disregarded because little implementation change is anticipated. Code testing is typically done as part of the execution of notebooks or scripts. The source-controlled scripts and notebooks that carry out the experiment steps provide artefacts including trained models, evaluation metrics, and visualisations.
No Continuous Deployment: CD is not taken into account because model version deployments are not common. The term “deployment” refers to the prediction service. Rather than deploying the full ML system, the process is simply concerned with deploying the trained model as a prediction service (for instance, a microservice with a REST API).
Absence of active performance monitoring: The procedure does not keep track of or log model actions and predictions, which are necessary to identify model performance decline and other behavioural deviations.
Level 1: Automation of ML Pipeline
By automating the ML pipeline, level 1 aims to continuously train the model, allowing for continuous model prediction service delivery. You must add automated data and model validation processes, pipeline triggers, and metadata management to the pipeline to automate the process of using new data to retrain models in production.
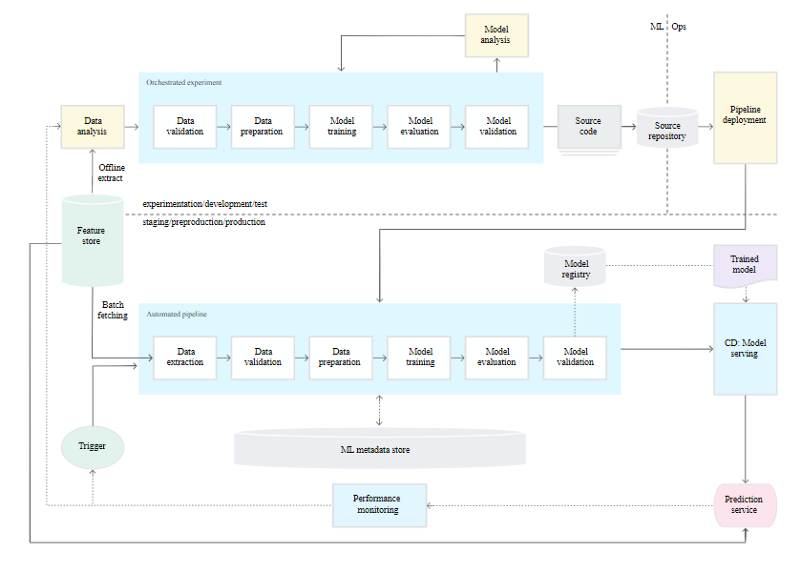
Rapid experiment: The ML experiment’s steps are planned. Because the transitions between steps are automated, trials may be iterated quickly, improving preparedness to put the entire pipeline into production.
CT of the model in production: Based on real-time pipeline triggers, the model is automatically trained using fresh data in production.
Experimental-operational symmetry: This principle of MLOps practice, which unifies DevOps, states that the pipeline implementation utilised in the development or experiment environment is also employed in the preproduction and production environments.
Pipelines and component code that is modularized: To build ML pipelines, components must be reusable, composable, and may be shared amongst ML pipelines. As a result, the source code for components must be modularized even while the EDA code might continue to reside in notebooks. Ideally, components should also be containerized to:
Separate the runtime for custom code from the environment for its execution.
Make the code reusable in both development and production settings.
Separate each pipeline component.Components may use distinct languages and libraries, as well as their version of the runtime environment.
Models are continuously delivered: New models that are trained on fresh data are constantly receiving prediction services from a production machine learning pipeline. The trained and validated model is used as a prediction service for online predictions during the automated model deployment process.
Pipeline deployment: At level 0, you launch an educated model into production as a prediction service. To deliver the trained model as the prediction service at level 1, you deploy an entire training pipeline that automatically and repeatedly runs.
Level 2: CI/CD Automation
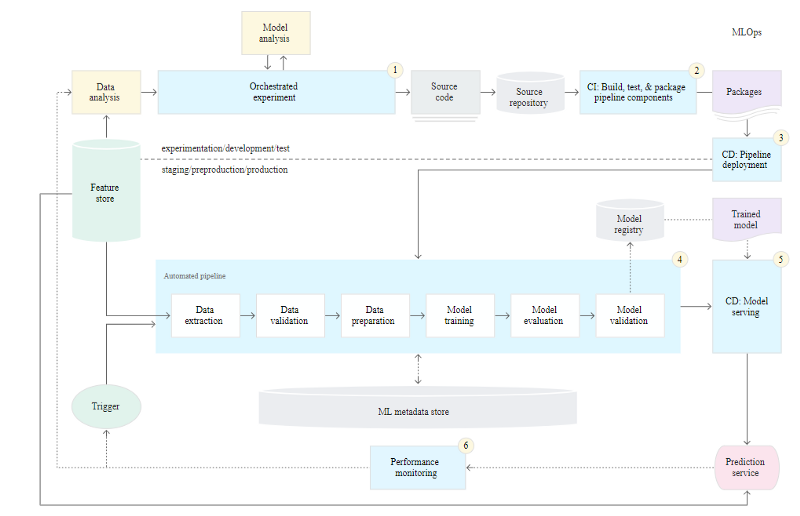
This MLOps setup includes the following components:
Source control
Test and build services
Deployment services
Model registry
Feature store
ML metadata store
ML pipeline orchestrator
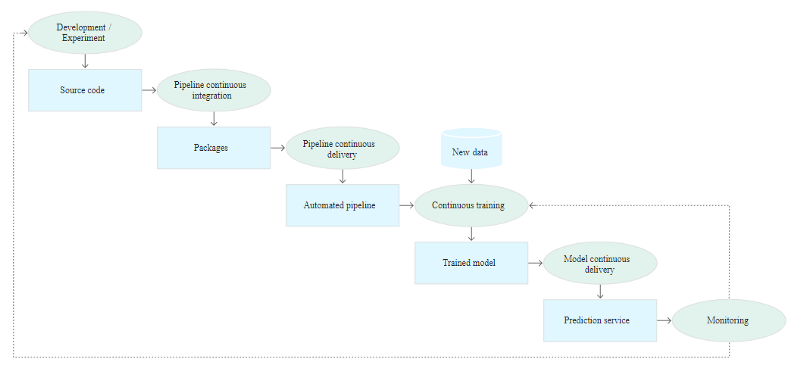
Development and experimentation: You coordinate the experiment phases as you repeatedly test out new ML algorithms and fresh modelling. The source code for the ML pipeline steps is the stage’s output, and it is subsequently uploaded to a source repository.
Continuous integration pipeline: You create source code and carry out various tests. Packages, executables, and artefacts are the outputs of this step, which will be deployed later.
Continuous delivery pipeline: You introduce the CI stage’s artefacts into the target environment. A deployed pipeline with the revised model implementation is the stage’s output.
Automated triggering: Based on a timetable or in reaction to a trigger, the pipeline is automatically carried out in production. A trained model that is uploaded to the model registry is the stage’s output.
Model continuous delivery: You provide a prediction service for the predictions using the trained model. A deployed model prediction service is the final product of this step.
Monitoring: Based on real-time data, you compile statistics on the model’s performance. This stage’s output is a trigger to run the pipeline or start a new cycle of experiments.
It’s an exciting time to be in this area, which has been picking up steam over the past several years thanks to the swift creation of new concepts. And as our reliance on big ML systems increases, I think it will become an even more crucial tool in a data scientist’s toolbox in the years to come.




