FireDucks: Supercharging Pandas for Lightning-Fast Data Analysis

Master's student @Trinity College Dublin | Loves solving complex problems through intelligent systems | Exploring jobs in tech
In the world of data science and analytics, pandas has long reigned supreme as the go-to library for data manipulation and analysis in Python. Its intuitive API, powerful features, and extensive documentation have made it an indispensable tool for data professionals across industries.
However, as datasets continue to grow in size and complexity, many data professionals find themselves bumping up against the limitations of pandas, particularly when it comes to performance with large-scale data, hampering productivity and slowing down insights.
Here comes FireDucks, a game-changing library that promises to revolutionise how we work with pandas. Developed by NEC, a company with over 30 years of experience in supercomputer technology, FireDucks aims to supercharge pandas operations without requiring users to change a single line of their existing code, offering the potential for dramatic performance improvements that could transform the way we approach data analysis tasks.
In this blog post, we have walked through a practical use-case to demonstrate FireDucks’ potential impact on data analysis workflows.
💪 Core Benefits of FireDucks
FireDucks offers several game-changing advantages for data professionals, such as:
Auto Parallelisation: FireDucks automatically splits your work across multiple CPU cores.
Performance Boost: Loading large datasets becomes lightning-fast.
Impressive Speed Improvements: Many operations run at least twice as fast as standard pandas. In some cases, you can see up to a 16x speedup!
Seamless Integration: No need to learn a new syntax or rewrite your code. FireDucks works with your existing pandas code, making it easy to adopt.
💡 Note: I have tried to evaluate it on standard Google Colab with only 2 CPU Cores. System with more CPU Cores might unlock more speedup.
To truly understand the power of FireDucks, we conducted a comprehensive performance analysis comparing it with the widely-used pandas library. Our use-case involved processing a wine reviews dataset, performing various common data manipulation and analysis tasks. Let’s dive into what we did and what we discovered.
📈 The Dataset and Operations
I have used a wine reviews dataset downloaded from Kaggle, containing thousands of entries with details about different wines, including their country of origin, points (ratings), price, variety, and more. On this dataset, I performed the following operations:
1. load_data: Loading the CSV file into memory
2. countna: Counting null values in the dataset
3. dropna: Removing rows with null values
4. query_1: Calculating average points by country (top 10)
5. query_2: Finding the most expensive wine
6. query_3: Calculating the number of reviews by variety (top 10)
7. query_4: Finding average price for each point value
These operations represent a mix of I/O, data cleaning, and analytical tasks that are common in many data science workflows.
💡 Note: the evaluate() is needed as you wanted to calculate query wise execution time correctly. For real program execution such explicit way of calling evaluate is not required.
📊 The Results
The performance comparison yielded impressive results in favor of FireDucks:
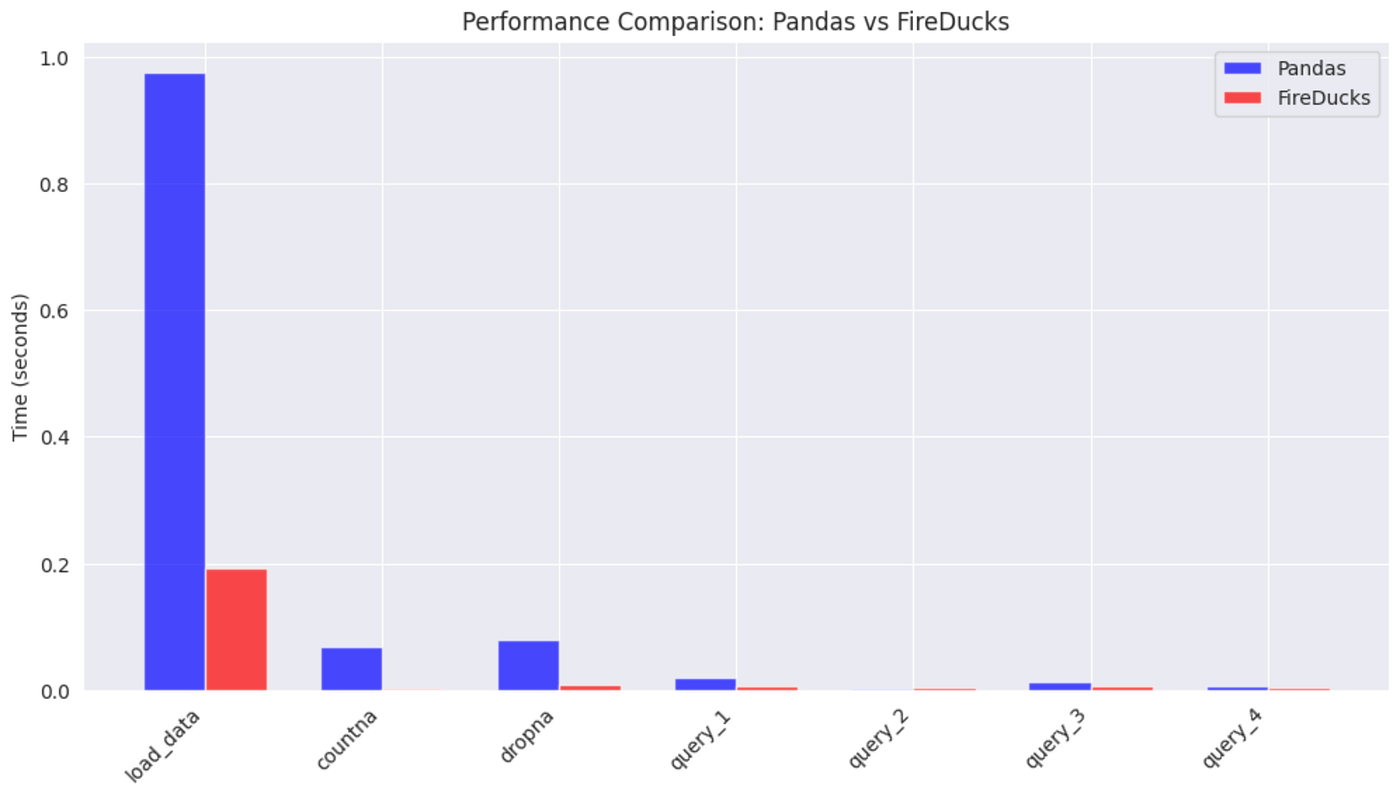
Data Loading: FireDucks loaded the data in 0.19 seconds compared to pandas’ 0.98 seconds — a 5x speedup!
Counting Null Values: FireDucks was 30x faster (0.002s vs 0.067s)
Dropping Null Values: FireDucks was 9x faster (0.009s vs 0.080s)
Query 1 (Avg. Points by Country): FireDucks was 2.6x faster (0.007s vs 0.019s)
Query 2 (Most Expensive Wine): pandas was slightly faster here (0.001s vs 0.005s for FireDucks)
Query 3 (Reviews by Variety): FireDucks was 2x faster (0.006s vs 0.012s)
Query 4 (Avg. Price by Points): FireDucks was 2x faster (0.003s vs 0.007s)
🔍 Analysis of the Results
1. Data Loading: The most significant improvement was in data loading. FireDucks’ ability to load a CSV file 5 times faster than pandas is a game-changer, especially when dealing with large datasets or when frequent data loading is required.
2. Null Value Operations: FireDucks showed exceptional performance in handling null values, with speedups of 30x for counting and 9x for dropping null values. This could significantly speed up data cleaning processes.
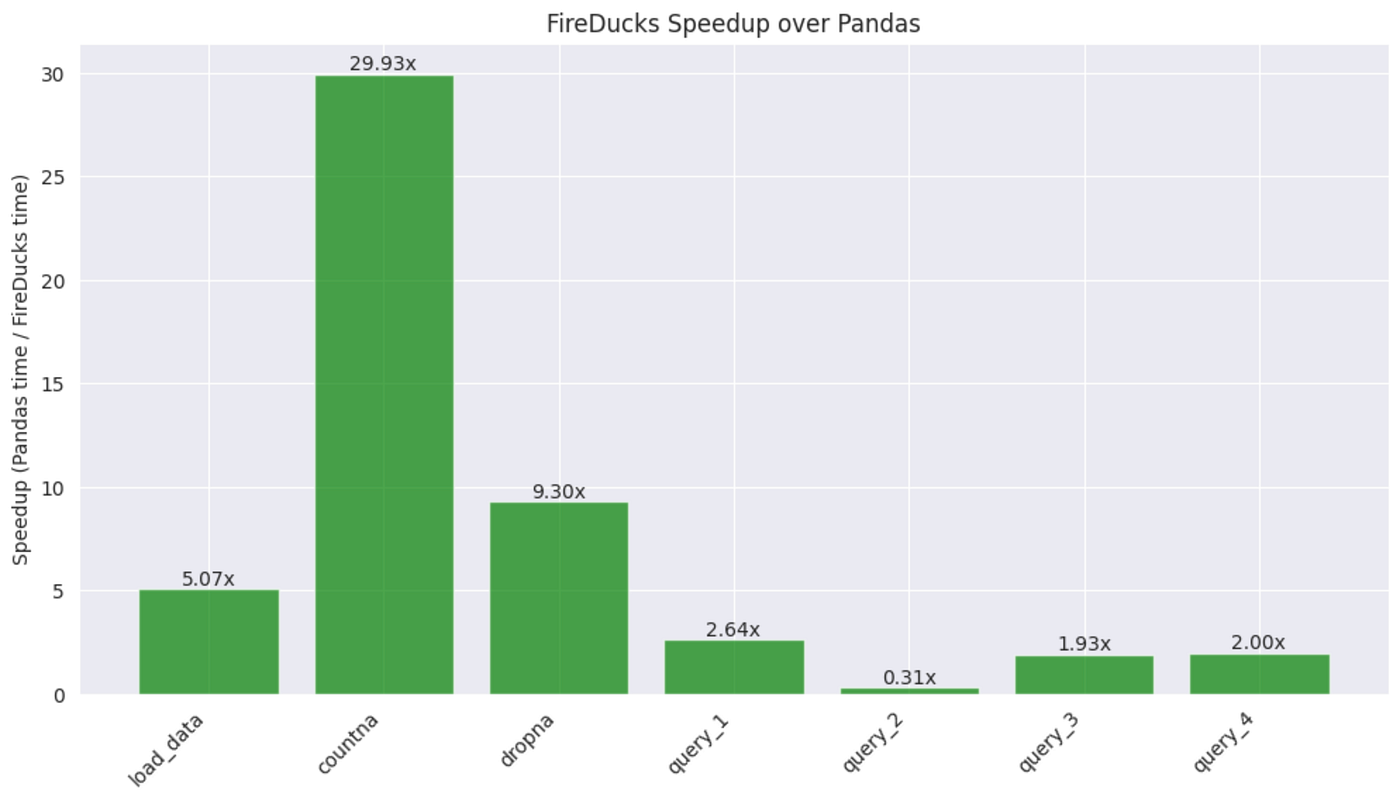
3. Analytical Queries: For most analytical queries (1, 3, and 4), FireDucks consistently performed about 2–2.6 times faster than pandas. This improvement can add up to substantial time savings in complex data analysis pipelines.
4. Simple Lookups: For very quick operations like finding the maximum value (Query 2), pandas performed slightly better. This suggests that for extremely simple operations on small datasets, the overhead of FireDucks’ parallelisation might not always be beneficial.
Our analysis clearly demonstrates that FireDucks can significantly outperform pandas, especially for data loading, null value operations, and complex analytical queries. The speedups range from 2x to 30x for various operations, with the most dramatic improvements seen in data loading and null value handling.
For data scientists and analysts working with large datasets or complex data pipelines, switching to FireDucks could result in substantial time savings and improved productivity.
Here is the Google Colab File in which I have carried out the same analysis end to end: FireDucks_Usecase.ipynb
📌 Practical Applications of FireDucks
FireDucks isn’t just about impressive benchmarks — it has real-world applications that can make a significant difference in your data workflows. Here’s where FireDucks really shines:
ETL Pipelines: Speed up your Extract, Transform, Load processes. Handle larger volumes of data in less time.
Batch Processing: Process multiple large files or datasets efficiently. Reduce overall processing time for batch jobs.
Large Dataset Analysis (1GB+): Work with gigabyte-scale datasets without breaking a sweat. Perform complex analyses on full datasets instead of samples.
Time Savings for Data Professionals: Spend less time waiting for calculations to complete. More time for analysis, insights, and decision-making.
📌 Availability and Accessibility
FireDucks is free, making it accessible to data professionals and organisations of all sizes.
FireDucks is only supported for Linux on X86 architecture at this moment. The windows and MacOS versions will be released soon as per the official website.
Since I’m having system with MacOS, therefore I considered experimenting on Google Colab with limited specification around 13 GB RAM and 2 CPU Cores. However, this broad availability ensures that most data scientists and analysts can incorporate FireDucks into their workflows, regardless of their preferred operating system.
📌 Getting Started with FireDucks
Getting started with FireDucks is straightforward. You can install it using pip, the Python package installer, with a simple command: pip install fireducks. Once installed, you can start using FireDucks by importing it in your Python script: import fireducks as fd. From there, you can use FireDucks just like you would use pandas, but with enhanced performance. For detailed instructions and advanced usage, check out the official FireDucks documentation.
Conclusion
FireDucks represents a significant leap forward in data processing capabilities. By leveraging supercomputer technology, it addresses the performance bottlenecks often encountered when working with large datasets in pandas. Our use-case demonstrated how FireDucks can dramatically reduce processing times and enable more comprehensive analyses. As datasets continue to grow in size and complexity, tools like FireDucks will become increasingly valuable in data science workflows.



